Behind every successful AI system, from space exploration to daily chats, is data annotation and labeling.
On one side of this mystery market are the buyers: Tier 1 AI labs like OpenAI, Anthropic, Meta, Google, Mistral, xAI, and Cursor, along with a fast-moving Tier 2 of niche large language models (LLMs). These companies rely on high-quality data and feedback to streamline their models’ behavior.
On the other side are the platforms (e.g., Surge AI, Micro1, Mercor, and Labelbox) that provide the infrastructure and services to make this possible, often using approaches like reinforcement learning from human feedback (RLHF). As a part of this evolving market, Lemon.io is an individual provider of software engineers for advanced data labeling.
Drawing on Lemon.io’s experience in sourcing and onboarding data annotators for both Tier 1 and Tier 2 labs, this article shows how these platforms create value for the companies building modern AI systems.
Data Annotation and Labeling Market Overview
The data annotation and labeling market is projected to grow from $1.2 billion in 2024 to $10.2 billion by 2034, highlighting the increasing importance of high-quality, context-driven datasets in AI systems.
This growth is already reflected in hiring trends. According to LinkedIn, data annotators rank among the top five most in-demand roles. Between 2023 and 2025 alone, more than 312,000 data annotation vacancies were posted on the platform.
This market scales by adding more experts, including software engineers, medical professionals, lawyers, insurance brokers, educators, and scientists, at a time when AI is supposed to reduce reliance on them. But apparently, for building reliable RLHF pipelines, human expertise remains highly relevant.
That’s why, similar to the data annotation and labeling market, the RLHF platform market is forecasted to grow from $2.8 billion in 2025 to $18.6 billion in 2034. The table below proves how lucrative it has already become.
Platform |
Total Funding |
Notable |
|---|---|---|
Scale AI |
$15.9B |
Meta holds 49% stakes |
Surge AI |
Bootstrapped to $1.2B |
$1B revenue in 4 years, under 100 people |
Mercor |
$484M |
$10B valuation (2025) |
Turing |
$270.2M |
Works on LLMs for OpenAI |
Labelbox |
$189M |
Google Vertex AI integration |
SuperAnnotate |
$67M |
Backed by NVIDIA and Databricks |
iMerit |
$36.3M |
Works on Amazon AI tools |
Prolific |
$33.5M |
$200M valuation |
Sama |
$85M |
GDPR-compliant |
Sources: Crunchbase, GetLatka, Investing.com, TechCrunch.
What is the RLHF platform?
RLHF enhances the data annotation and labeling process because it turns real human judgment into measurable model training signals. For instance, InstructGPT is a class of OpenAI models based on GPT-3 that was improved with RLHF.
RLHF is a post-training method that improves outputs of large language models (LLMs) and other generative AI models by using human preference data. This method guides the model toward responses that better match real-world expectations.
The aim of RLHF isn’t to make the model more truthful, but to ground it in what people prefer in certain use cases (culture, domain, organization, certain human values, or context). For instance, to the user’s question in chatbots like ChatGPT, Claude, or Gemini: “Is AI going to replace all jobs?”
The preferred answer would be: “No, AI will create more jobs than it replaces.”
But a more accurate answer could be: “It depends on the industry. Some roles will be automated, others will grow, and the transition can be uneven and disruptive.”
The preferred answer might be better for people who value reassurance and simplicity more than nuance.
The RLHF training improves an AI model’s responses by:
- Collecting human preferences: annotators compare model outputs and pick the better one
- Training a reward model: a secondary model learns to predict which outputs humans prefer (usually a pre-trained model with the help of supervised learning)
- Fine-tuning via RL for policy optimization: the main model (policy) is optimized using that reward signal
RLHF platforms aim to solve a fundamental problem in natural language processing (NLP): how do you teach a model to be helpful, harmless, and honest when those qualities are hard to specify mathematically?
The Industries Shaping Demand for Expert Data Annotation
RLHF demand is strongest in domains where model errors carry meaningful consequences, whether in human safety, digital security, revenue, compliance, or highly technical workflows.
Early-generation models needed annotators to label images or flag toxic text: tasks that required attention but not deep expertise. Today’s frontier algorithms are expected to reason through medical diagnoses, write production-grade code, navigate legal ambiguity, and explain scientific concepts accurately. Evaluating whether a model does any of these things well requires someone who knows the domain.
Here’s how different industries can leverage data annotation for the model training process:
Industry |
Why RLHF Matters |
What Expert Feedback Improves |
|---|---|---|
Healthcare & Life Sciences |
Diagnostic support, clinical reasoning, patient-trial matching |
Medical image interpretation, patient context, treatment recommendations |
BFSI (Banking, Financial Services, Insurance) |
Fraud detection, underwriting, claims, and compliance |
Risk judgment, anomaly detection, policy interpretation |
LegalTech |
Contract review, legal research, regulatory interpretation |
Clause analysis, precedent relevance, ambiguity handling |
Linguistics / Multilingual AI |
Translation, localization, conversational systems |
Tone, cultural nuance, and terminology precision |
STEM (Science, Tech, Engineering, Math) |
Scientific reasoning, coding, simulations, and engineering workflows |
Technical correctness, formula interpretation, design logic |
How RLHF Platforms Differ
Not all RLHF platforms operate at the same level, and treating them as interchangeable can lead to poor sourcing, mismatched quality, or unnecessary cost. Some platforms are built for frontier AI labs that require massive annotation scale, others focus on enterprise-grade data quality, while a smaller group differentiates through ethical labor models or specialized expert networks.
To make sense of this fragmented market, we grouped leading RLHF platforms across funding, positioning, and the types of AI organizations they serve.
Enterprise-Grade Scaling Giants
RLHF platforms under this category are built for scale and enterprise delivery, often working directly with frontier AI labs and large organizations.
Scale AI
Scale AI helps AI labs and enterprises convert massive volumes of raw data (images, videos, text conversations, or code) into structured training data that AI models can use.
At its core, the company breaks large labeling projects into smaller tasks, distributes them across a global workforce through AI platforms like Oultlier and Remotasks, applies software-driven quality control and consensus scoring, and delivers refined outputs back to clients.
Scale AI’s value lies in delivering RLHF services, LLM evaluation, enterprise software, task routing, and QA at scale for AI development.
In 2025, Meta invested $14.3 billion in Scale AI to enhance AI initiatives. After this, clients such as Google decided to shift part of the AI training workload to Scale AI’s rivals.
Founded: 2016
Clients: Meta, Microsoft, OpenAI, Etsy, Flexport, General Motors
Source: Scale AI
What this tells you: Scale AI is used by major labs and enterprises that need a mature partner for high-volume model training, evaluation, and deployment support.
Labelbox
A platform for managing data labeling and curation workflows, where you organize and control how feedback is collected. Originally, Labelbox focused on simpler data labeling, now expanded into RLHF and multimodal evaluation.
In 2025, the company expanded its platform with multimodal chat tooling, built-in code runners, model integrations like GPT-4o and Amazon Nova, and new enterprise RLHF workflows, reflecting a broader shift from “labeling software” toward full AI data infrastructure.
Labelbox worked with STEM PhDs to help a major AI lab improve how its model handled science and math tasks, using expert-reviewed prompts and evaluations to strengthen reasoning beyond basic data labeling.
Founded: 2018
Clients: NASA, Walmart, Procter & Gamble, Genentech
Source: Labelbox
What this tells you: Labelbox is used by enterprises that need control, compliance, and structured workflows.
Surge AI
A large-scale data provider that supplies high-quality human feedback to train and evaluate AI models. The platform specializes in RL environments, RLHF, Supervised Fine-Tuning (SFT), and internationalization (to train AI on different languages and cultural values).
Through the public-facing Taskup.ai, DataAnnotation.tech, and Gethybrid.io platforms, which reportedly belong to Surge AI, the company recruits and manages a large global pool of freelancers while emphasizing highly educated, domain-specific talent for more complex tasks. This includes medical doctors ($200–500/hour), PhD researchers ($150–350/hour), and software engineers ($100–300/hour), positioning the company toward higher-precision data workflows rather than generic labeling.
Founded: 2020
Clients: OpenAI, Google, Microsoft, Meta, Anthropic
What this tells you: Surge is trusted for high-stakes, production-level AI training, where both quality and scale matter.
All of the above players dominate high-volume RLHF pipelines and are often embedded in environments where throughput and reliability are critical.
Expert-Centric Platforms
These platforms sit between traditional data vendors and hiring solutions. Instead of just producing labeled data, they also provide access to human judgment.
Micro1
A marketplace that quickly connects you with vetted experts to generate training data and evaluate AI outputs. It began as an AI recruiting platform with a flagship product, Zara, an AI recruiter that conducts asynchronous technical interviews and automatically scores candidates in more than 20 languages, accepting roughly 1% of applicants.
From the recruiting platform, Micro1 has gradually expanded into the AI training market. In December 2025, the company surpassed $100 million in ARR.
Founded: 2022
Clients: Microsoft and Fortune 100 companies
Source: Micro1
What this tells you: Micro1 is optimized for speed. Clients use it when they need expert talent quickly rather than engage in long procurement cycles.
Products: Merit (AI-driven talent evaluation and ranking), Zara (AI recruiter/agent for sourcing and vetting candidates), and a data platform for managing expert workflows and training tasks.
Turing
A global talent platform that provides engineers and AI trainers to support development and model improvement. The company expanded from a developer marketplace into RLHF and AI training workflows. Thanks to the platform’s long presence on the market, Turing has access to over 4 million coders worldwide.
This platform is an official partner of OpenAI in creating and training LLMs.
Founded: 2018
Clients: Works with leading AI labs and enterprise teams
Pitch: enterprise-grade talent supplier.
Core strength: Turing is used when companies need to scale engineering and AI training capacity quickly.
Mercor
An AI-driven hiring platform that matches highly specialized experts (like lawyers or analysts) to RLHF tasks. This was originally a recruiting marketplace, which, like many of their competitors, has evolved into an AI training with human-in-the-loop (HITL) company. Mercor has a database of more than 30,000 highly qualified pre-vetted experts across different fields of study.
Founded: 2023
Clients: OpenAI, Anthropic, Google
Source: Mercor
What this tells you: Mercor focuses on high-skill, domain-specific human input where generic labeling isn’t enough.
While Turing focuses on scaling engineering capacity, Mercor focuses on optimizing the quality of human judgment used in model training.
Open-Source & Infrastructure
This category enables companies to own the RLHF pipeline end-to-end.
OpenRLHF
OpenRLHF is an open-source framework that lets your team build and run RLHF pipelines in-house instead of outsourcing them.
Founded: Open-source project, 2023
Users: Internal machine learning (ML) teams, research labs
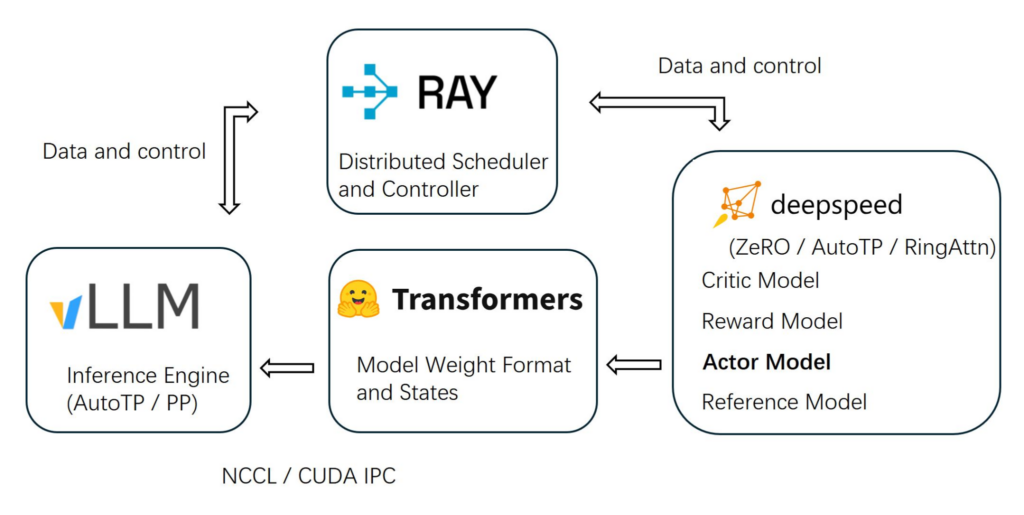
Source: OpenRLHF
Key components of this platform are:
- DeepSpeed. The training engine that runs RLHF. It manages multiple models (actor, reward, critic, reference) and optimizes them using feedback, while handling large-scale, distributed training efficiently.
- Transformers.The layer where the model itself lives. It stores and manages the model’s weights and states as they get updated during training.
- Ray. The orchestrator that coordinates everything. It distributes tasks across machines and GPUs, making sure training runs smoothly at scale.
- LLM Inference Engine. The production layer where the trained model is used. It serves responses to users and is optimized for speed and efficiency.
- NCCL / CUDA IPC. Low-level GPU communication tools that allow different machines and GPUs to exchange data quickly during training.
What this tells you: Teams using OpenRLHF prioritize control, privacy, and customization over convenience.
Summary of RLHF Platforms Listing
These platforms all operate in the same data annotation and labeling market, but solve different problems.
Scale AI and Surge AI act as execution engines. They handle the heavy lifting of turning model improvement into a repeatable RLHF process, running large, coordinated workflows that generate and evaluate data at scale.
Labelbox focuses on control. It gives teams a structured way to define, track, and refine how feedback is collected and applied, which becomes critical when consistency and oversight matter.
Turing, Mercor, and Micro1 shift the focus to people. Instead of just processing data, they determine who produces it. Their value comes from sourcing, evaluating, and deploying human expertise (engineers, analysts, or domain specialists) into the training loop.
OpenRLHF moves in a different direction. It allows teams to internalize the entire process by building their own pipelines for model alignment with human preferences instead of relying on external providers.
Lemon.io also provides access to pre-vetted, highly skilled human annotators, handling sourcing and onboarding so teams can start labeling data without delays.
Beyond offering high-quality data and talent, how long will RLHF systems remain relevant in today’s AI market?
How Long Will AI Models Rely on Human Judgement?
RLHF platforms pose the most controversial questions of all: will AI completely replace human judgment, or will AI models remain dependent on humans?
In healthcare, finance, legal systems, or complex technical domains, it’s difficult to fully automate human judgment because “correct” behavior often depends on nuance, tradeoffs, and context. At the same time, advanced RL workflows are expensive, sometimes reaching $20,000 per scenario, which means not every use case justifies deep human feedback loops.
Yet we can assume that the RLHF market won’t go away until AI systems can reliably reason, self-correct, and excel at decision-making without continuous external supervision.
For now, models learn from people, and people rely on models. The loop that isn’t going anywhere anytime soon.
As Time has noted, RLHF platforms embed collective human intelligence into artificial intelligence. But big tech companies are undervaluing their impact by refusing to provide fair and safe working conditions, as if they want to keep the need for data annotations a huge secret so as not to undermine the intelligence component in their artificial models.
This is where platforms like Lemon.io play a critical role; our talent acquisition team helps AI companies connect with vetted engineers and domain experts through transparent, ethically structured engagement models. By managing the full talent lifecycle, from sourcing and onboarding to payments and operational support, we help reduce risks while creating safer, more sustainable working conditions for both businesses and contributors.
Another topic worth covering in this section is that the cost of training AI models has been steadily rising over the years, as illustrated in this graph:
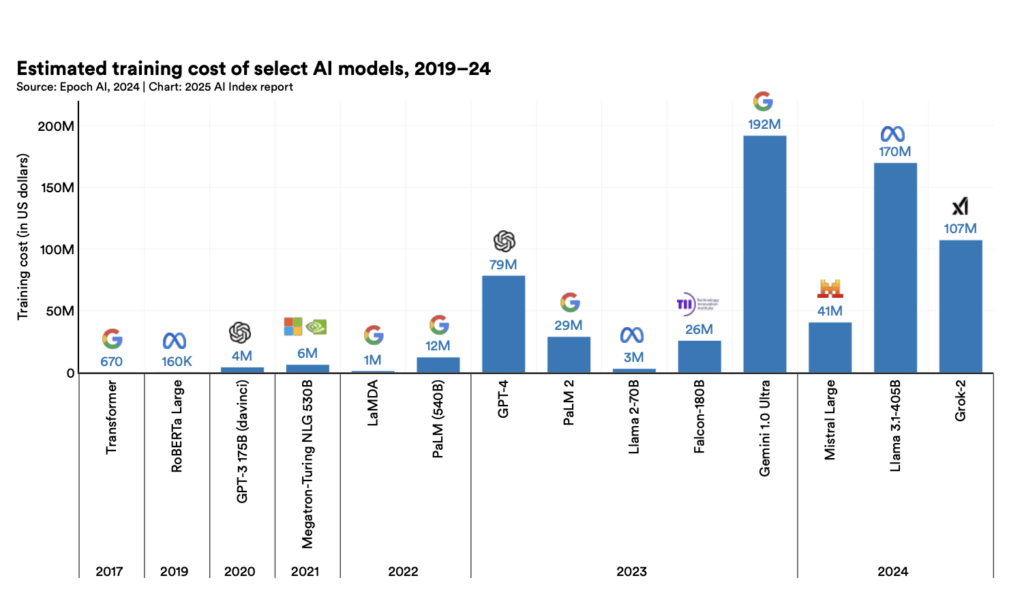
Source: Artificial Intelligence Index Report 2025
With publicly available data collection shrinking, synthetic data still producing inconsistent outcomes in many domains, hardware costs rising, and expert-reviewed annotation remaining critical, how much will AI models of the future cost?
Anthropic CEO Dario Amodei has said that leading AI companies may soon spend nearly $1 billion on a single model training run, with as many as ten $10 billion-scale training runs possible within the next two years. This can significantly increase the pricing of user-facing AI tools.
The industry may soon face a paradox: as compute costs soar, and public data quality declines, the limiting factor for better AI may not be chips alone, but access to trustworthy human expertise.
If future models’ learning process requires fewer but significantly better annotations, then the companies that win may not simply be those spending most on GPUs, but those building the strongest systems for sourcing, refining, and retaining expert human judgment.
That raises a larger strategic question: in the race to build more intelligent machines, will companies continue treating human expertise as a disposable input, or recognize it as one of AI’s most valuable infrastructures?